Introduction
Dans mon homelab, j’ai souhaité aller plus loin dans l’automatisation en déployant un cluster Kubernetes complet sur Proxmox, en m’appuyant sur des outils d’infrastructure as code et d’automatisation comme Ansible. L’objectif était de pouvoir provisionner rapidement un cluster k8s reproductible, prêt à accueillir des workloads, tout en gardant la maîtrise de chaque étape du déploiement via du code. Ce processus d’évolution m’a naturellement conduit vers Kubespray.
Contexte
Après avoir initialement installé un cluster Kubernetes de façon manuelle avec kubeadm, j’ai constaté que le processus était particulièrement fastidieux. Cette expérience m’a convaincu dans la nécessité d’automatiser et de standardiser le déploiement, afin de gagner en reproductibilité et en efficacité.
C’est là que Kubespray intervient, ce projet open source propose des playbooks Ansible prêts à l’emploi pour installer, configurer et maintenir un cluster Kubernetes avec une approche 100% as code. Contrairement à kubeadm, il offre un contrôle fin sur les composants du cluster (CRI, CNI, DNS, etc.) tout en restant automatisé et reproductible. Dans cet article, je détaille la démarche suivie, les choix techniques réalisés, et les outils utilisés pour atteindre cet objectif.
Logo Kubespray
Prérequis
Avant de commencer le déploiement, il est nécessaire de disposer des ressources suivantes :
Infrastructure :
- Au moins 24 GB de RAM disponible sur l’hyperviseur Proxmox
- 150 GB de stockage libre
- Accès réseau avec attribution d’IP statiques
- Clé SSH pour l’accès aux VMs
Composants
- Proxmox 8.X+ : Fournit l’infrastructure pour exécuter et gérer des machines virtuelles.
- Ansible 2.16+ : Outil d’automatisation utilisé par Kubespray pour déployer et configurer Kubernetes.
- Terraform 1.10+ & Packer 1.12+ : Pour automatiser la création et la configuration des VMs.
Architecture cible du cluster
Le cluster sera composé de trois nœuds avec le dimensionnement suivant :
| Rôle | Hostname | vCPU | RAM | Stockage |
|---|---|---|---|---|
| Control Plane | k8s-master-01 | 4 | 8 GB | 50 GB |
| Worker Node | k8s-worker-01 | 4 | 8 GB | 50 GB |
| Worker Node | k8s-worker-02 | 4 | 8 GB | 50 GB |
Architecture cible
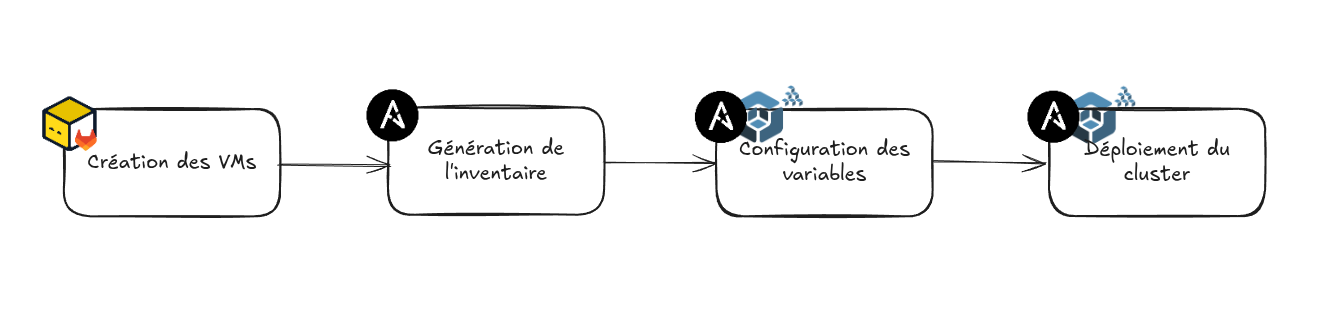
Création des VMs
Pour mon homelab, j’ai opté pour une architecture simple composée de trois VMs : un control plane et deux worker nodes.
Ce choix s’explique par plusieurs raisons :
- Simplicité pour l’apprentissage : Avec trois nœuds, le cluster reste simple à gérer tout en permettant d’expérimenter la plupart des fonctionnalités Kubernetes (répartition de charge, affinité des pods, tolérance aux pannes, etc.).
- Tolérance aux pannes des workers : Deux workers offrent la possibilité de tester des scénarios de panne d’un nœud et d’observer le comportement de Kubernetes lors du rescheduling des pods.
- Maîtrise des ressources : Ce dimensionnement reste raisonnable en termes de ressources consommées (4 vCPU, 8 Go RAM, 50 Go stockage par VM), ce qui est important dans un contexte de homelab.
Note sur la haute disponibilité : Cette architecture comprend un seul control plane. Pour une véritable haute disponibilité en production, il serait nécessaire de déployer au minimum 3 control planes (nombre impair pour le quorum etcd) avec un load balancer devant les API servers ou bien d’avoir des instances dédiés pour etcd hors du cluster. Dans le cadre de ce homelab, un seul control plane suffit pour les besoins d’apprentissage et d’expérimentation.
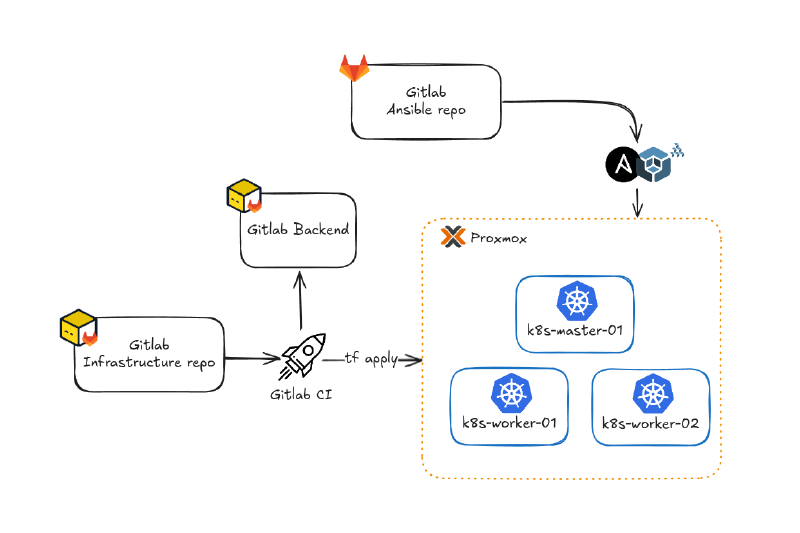
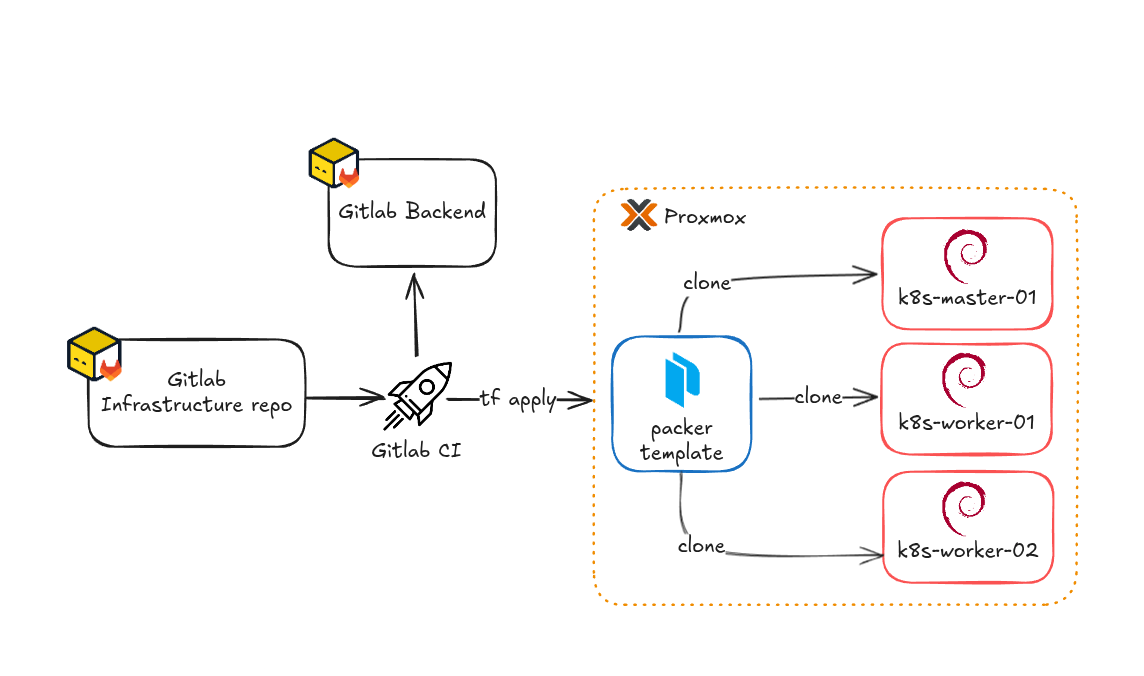
Une fois le dimensionnement défini, passons à la création des VMs. Pour cela, j’ai utilisé Terraform et Packer, ce qui me permet de déployer rapidement mon infrastructure de manière totalement automatisée. J’explique en détail cette approche, notamment la création de templates Proxmox avec Packer et leur déploiement avec Terraform, dans cet article.
| |
Après l’application du code Terraform, les trois machines virtuelles sont déployées sur Proxmox. Chaque VM est associée à un ou plusieurs tags parmi : (k8s_cluster, kube_control_plane, etcd, kube_node). Ces tags faciliteront la génération de l’inventaire pour Kubespray que je détaille plus bas dans l’article.
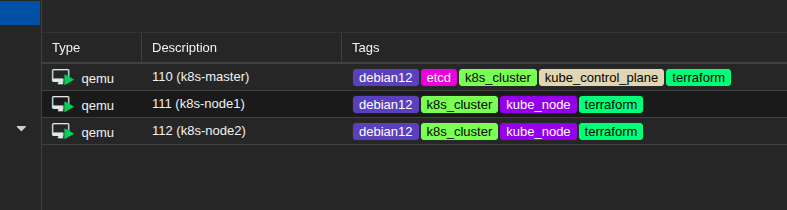
VMs dans Proxmox
Configuration réseau et accès SSH
Grâce à l’utilisation de Cloud-Init lors du processus de la création des VMs (via le template Packer et l’argument initialization dans la ressource proxmox_virtual_environment_vm du provider Terraform), la configuration réseau et l’accès SSH sont automatisés :
- Adresse IP statique : Chaque VM reçoit directement son IP statique lors du déploiement, définie dans la section
ip_configde Terraform. Cela évite toute configuration manuelle post-déploiement. - Clé SSH : La clé publique SSH est injectée automatiquement dans chaque VM via Cloud-Init, ce qui permet une connexion immédiate sans avoir à copier la clé manuellement.
Ce processus permet de gérer toutes les VMs via Ansible dès leur création, sans intervention manuelle supplémentaire. Dans mon cas, je peux donc directement utiliser les playbooks Kubespray.
Note de sécurité : Dans un environnement de production, il est recommandé de gérer les secrets (tokens API Proxmox, clés SSH, etc.) avec des outils dédiés comme Ansible Vault ou des gestionnaires de secrets externes.
Les ressources sont désormais prêtes et configurées, nous pouvons maintenant passer à la mise en place du cluster Kubernetes avec Kubespray.
Mise en place de Kubespray
Cloner et configurer le dépôt Kubespray
J’ai intégré Kubespray dans mon projet en tant qu’un submodule git. Ceci permet d’inclure un autre repository tout en gardant son historique séparé. Cela facilite la gestion des dépendances et permet de suivre une version précise de Kubespray, la mettre à jour facilement, et avoir les évolutions du projet sans mélanger les codes sources.
| |
Afin de fixer la version du submodule sur un tag ou un commit spécifique, il faut se rendre dans le répertoire du submodule et checkout sur le commit ou tag désiré dans le projet. Ensuite, il faut retourner dans le répertoire principal du projet, commit les changements et pousser les modifications.
| |
Il est important de fixer la version de Kubespray afin de garantir la reproductibilité des déploiements et d’éviter toute instabilité liée à des changements non maîtrisés dans le projet en amont.
Une fois le projet Kubespray intégré et configuré dans le dépôt Ansible, on peut passer à la génération de l’inventaire pour Kubespray.
Création de l’inventaire Kubespray
Pour la partie inventaire ansible pour Kubespray, j’ai choisi la solution de l’inventaire dynamique avec Proxmox. Ceci permet d’avoir un inventaire qui est constamment à jour, car il est chargé sur chaque lancement de playbook, ce qui évite une maintenance manuelle du ficher d’inventaire.
| |
L’inventaire ci-dessus permet de récupérer toutes les VMs dans proxmox et de les regrouper par tags proxmox_tags_parsed et de configurer la variable ansible_host de chaque entrée dans l’inventaire avec l’IP associée à chaque VM.
Dans le cas de Kubespray, il faut respecter la nomenclature des tags comme c’est écrit dans la documentation, car c’est ce qui va servir à lancer les playbooks sur les bons hôtes.
Pour générer l’inventaire, j’utilise la commande ci-dessous, où l’option --graph va permettre de rendre la sortie de la commande un peu plus visuelle afin de bien distinguer les groupes et les hôtes de l’inventaire ansible.
| |
Et dans mon cas ça donne le résultat suivant :
| |
Une fois l’inventaire en place, je peux tester la connectivité des VMs via la commande ad hoc ci-dessous qui utilise le module ansible ping :
| |
Ce qui donne le résultat suivant :
| |
Maintenant que je dispose de l’inventaire dynamique pour Proxmox et de machines virtuelles accessibles, je vais pouvoir passer à la partie customisation de mon cluster K8s.
Personnalisation des variables
Afin de pouvoir customiser le cluster Kubernetes, il va falloir passer par les group_vars ansible. Grâce à ces variables, nous allons pouvoir configurer différents aspects du cluster tel que :
- Paramètrage Kubernetes (Version de kube, réseau interne, DNS,…)
- Container Runtime Interface (CRI)
- Container Network Interface (CNI)
- Container Storage Interface (CSI)
- Configuration ETCD
- Addons et composants optionnels (ArgoCD, Helm, cert-manager, MetalLB, …)
- Et bien d’autres choses…
Ces variables sont organisées dans différents fichiers de l’inventaire pour une meilleure structuration de la configuration :
| |
Pour plus d’informations à propos de la configuration possible du cluster Kubernetes et des composants disponibles, il faut se référer à la documentation de Kubespray.
Note technique : Dans le cadre de cet article, j’utilise principalement les configurations par défaut proposées par Kubespray. L’objectif est de montrer le processus de déploiement plutôt que de justifier des choix techniques spécifiques pour chaque composant (CNI, CRI, etc.). Ces choix peuvent être adaptés en fonction des besoins spécifiques de chaque projet.
La configuration cible du cluster Kubernetes a été définie, la prochaine étape va être le déploiement !
Déploiement du cluster Kubernetes
Avant de lancer le déploiement avec ansible, j’ai besoin de configurer mon environnement, pour ce faire, je passe par un venv python afin de fixer la version d’ansible ainsi que de mes dépendances dans le but d’isoler le tout pour éviter les potentiels conflits avec d’autres projets. Le venv va également permettre d’avoir un environnement reproductible ce qui est crucial pour exécuter les déploiements de manière identique.
| |
Une fois l’environnement prêt, il est enfin temps de passer au déploiement du cluster, en lançant le playbook cluster.yml et en utilisant l’inventaire dynamique ansible pour Proxmox configurer au préalable.
| |
Une fois le playbook terminé, le cluster Kubernetes est prêt à l’emploi avec la configuration définie plus haut.
| |
Vérification du cluster
Une fois le déploiement terminé, il est essentiel de vérifier que le cluster Kubernetes est opérationnel et que tous les composants fonctionnent correctement. Pour cela, plusieurs commandes kubectl permettent de valider l’état des nœuds et des pods.
Pour valider l’état des nœuds du cluster :
| |
Résultat obtenu :
| |
Tous les nœuds doivent être dans l’état Ready, ce qui indique qu’ils sont prêts à exécuter des workloads.
Pour s’assurer que tous les pods sont en état de fonctionnement, il faut passer par la commande :
| |
Résultat obtenu :
| |
Tous les pods doivent être dans l’état Running. Cela garantit que les composants du cluster sont correctement déployés et fonctionnels.
Ces vérifications permettent de valider que le cluster Kubernetes est prêt à accueillir des workloads et que les services essentiels sont opérationnels.
Résultat
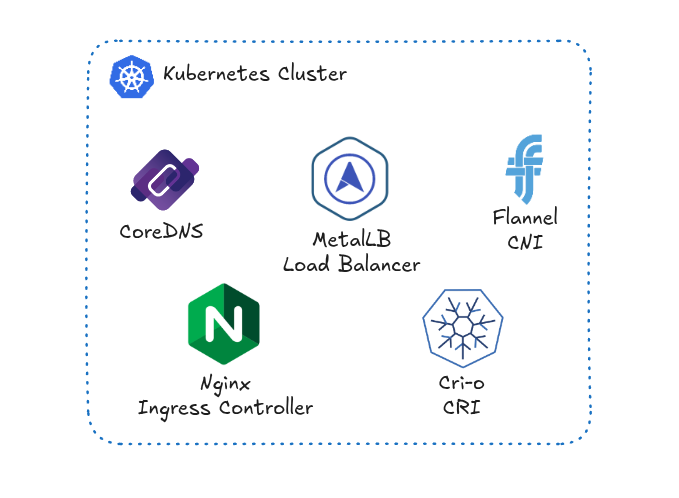
Cluster Kubernetes post déploiement
Opérations post-déploiement
Gestion du cycle de vie
Kubespray ne se limite pas au déploiement initial, il propose également des playbooks pour gérer le cycle de vie complet du cluster :
Ajout de nœuds :
| |
Mise à jour du cluster :
| |
Réinitialisation complète :
| |
Conclusion
L’automatisation du déploiement d’un cluster Kubernetes avec ansible via le projet Kubespray permet de gagner en fiabilité, en rapidité et en reproductibilité, ce qui est essentiel pour moi dans mon contexte de homelab.
Grâce à l’inventaire dynamique et aux variables ansible, il est simple d’adapter la configuration du cluster en fonction de mes besoins, tout en gardant la maîtrise sur chaque composant. Cette approche permet également de faciliter la maintenance et l’évolution du cluster k8s, car tout est fait as code et que kubespray prévoit également des playbooks pour ajouter un nœud dans le cluster (scale.yml) ou même remettre le cluster à zéro (reset.yml).
Workflow